Glasgow Haskell 编译器和 LLVM
如果您仔细阅读了 LLVM 2.7 版本说明,您会发现新的外部用户之一是 Glasgow Haskell 编译器 (GHC)。作为 GHC LLVM 后端 的作者,我被邀请写一篇关于后端设计以及使用 LLVM 的经验的文章。这就是这篇文章 :)。我从去年七月开始着手这个后端,将其作为计算机科学学士学位荣誉论文的一部分。目前,后端在 Linux x86 上非常稳定且功能强大,能够自举 GHC 本身。其他平台尚未获得任何关注。
什么是 GHC 和 Haskell
GHC 是 Haskell 的编译器,Haskell 是一种标准化的、惰性的、函数式编程语言。Haskell 支持诸如带类型推断的静态类型、惰性求值、模式匹配、列表推导、类型类和类型多态性等功能。GHC 是最流行的 Haskell 编译器,它将 Haskell 编译成原生代码,并支持 X86、PowerPC 和 SPARC。现有管道
在添加 LLVM 后端之前,GHC 已经支持两个后端,一个 C 代码生成器和一个原生代码生成器 (NCG)。C 代码生成器是第一个实现的后端,它工作得很好,但速度慢且脆弱,因为它使用许多 GCC 特定扩展,并且需要对 GCC 生成的汇编代码进行后处理以实现无法在 C 代码中完成的优化。原生代码生成器稍后启动以避免这些问题。它的速度大约是 C 后端的 2-3 倍,并且通常将 Haskell 程序的运行时减少约 5%。GHC 开发人员希望在下一个主要版本中弃用 C 后端。
为什么使用 LLVM 后端?
- 卸载工作:构建一个高性能编译器后端是一项巨大的工作,例如 LLVM 大约在 10 年前开始。展望未来,LLVM 后端应该比 C 后端或 NCG 更容易维护和扩展。它还将受益于 LLVM 的任何未来改进。
- 优化过程:GHC 在生成快速 Haskell 程序方面做得很好。但是,它当前没有实现许多低级优化(尤其是需要机器特定知识的优化)。使用 LLVM 应该可以免费获得其中大部分优化。
- LLVM 框架:LLVM 最吸引人的特性可能是它从一开始就被设计为一个编译器框架。对于像 GHC 开发人员这样的研究人员来说,这是一个巨大的优势,使 LLVM 成为一个非常有趣的游乐场。例如,在 LLVM 后端公开发布后的几天内,一位开发人员 Don Stewart 写了一个遗传算法,用于找到用于各种 Haskell 程序的最佳 LLVM 优化管道(您可以在他的博客文章中找到关于此的更多信息 这里)。
展示速度
不过,现在已经足够多的论证了,让我们直接跳进去看看 GHC 的 LLVM 后端在行动中。我还会借此机会做一些 Haskell 推广,所以您已经得到警告了 :)。为了解决一个简单的问题,让我们找到一个小于 100 万的起始数字,它能生成最长的 问题 冰雹序列。冰雹序列是从起始数字 n 生成的数字序列,遵循以下规则
- 如果 n 是偶数,下一个数字是 n/2
- 如果 n 是奇数,下一个数字是 3n + 1
- 如果 n 是 1,停止。
#include <stdio.h>
int main(int argc, char **argv) {
int longest = 0, terms = 0, this_terms = 1, i;
unsigned long j;
for (i = 1; i < 1000000; i++) {
j = i;
this_terms = 1;
while (j != 1) {
this_terms++;
j = j % 2 == 0 ? j / 2 : 3 * j + 1;
}
if (this_terms > terms) {
terms = this_terms;
longest = i;
}
}
printf("longest: %d (%d)\n", longest, terms);
return 0;
}
--------
import Data.Word
collatzLen :: Int -> Word32 -> Int
collatzLen c 1 = c
collatzLen c n | n `mod` 2 == 0 = collatzLen (c+1) $ n `div` 2
| otherwise = collatzLen (c+1) $ 3*n+1
pmax x n = x `max` (collatzLen 1 n, n)
main = print . solve $ 1000000
where solve xs = foldl pmax (1,1) [2..xs-1]
使用各种后端编译 Haskell 解决方案,得到以下运行时
- GHC-6.13 (NCG):2.876 秒
- GHC-6.13 (C):0.576 秒
- GHC-6.13 (LLVM):0.516 秒
- Clang-1.1:0.526 秒
- GCC-4.4.3:0.335 秒
我选择这个示例程序的原因之一是,我想通过展示 Haskell 的并行化解决方案的简单性来炫耀一下 Haskell
import Control.Parallel
import Data.Word
collatzLen :: Int -> Word32 -> Int
collatzLen c 1 = c
collatzLen c n | n `mod` 2 == 0 = collatzLen (c+1) $ n `div` 2
| otherwise = collatzLen (c+1) $ 3*n+1
pmax x n = x `max` (collatzLen 1 n, n)
main = print soln
where
solve xs = foldl pmax (1,1) xs
s1 = solve [2..500000]
s2 = solve [500001..999999]
soln = s2 `par` (s1 `pseq` max s1 s2)
就是这样!我们只需将问题分成两部分,然后使用 Haskell 的 'par' 和 'pseq' 结构将它们组合起来,告诉编译器并行运行两个部分 's1' 和 's2'。运行时(当然使用 LLVM)
- GHC-6.13(并行,LLVM): 0.312
最后,让我们看看一个更大、更“现实”的程序,看看 LLVM 后端的表现。为此,我们将使用 HRay,一个用 Haskell 实现的光线追踪器。使用它生成下面的图像,我们得到以下运行时

- GHC (NCG) 29.499
- GHC (C) 29.043
- GHC (LLVM) 20.774
后端概述
让我们快速看看 LLVM 后端需要完成的工作。GHC 使用两个主要的中间表示形式来编译 Haskell,第一个是 Core。Core 是一种函数式语言,基本上是类型化 lambda 演算的一种形式,GHC 在此形式中完成大部分优化工作。还有一种名为 STG 的 IR,它与 Core 非常相似,但对于过程代码生成来说稍微容易处理一些。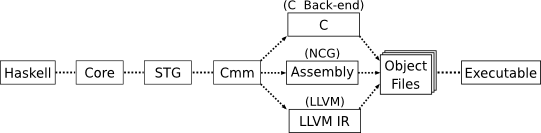
第二个主要 IR 是 C minus minus (Cmm),这是一种低级命令式语言,旨在充当高级 Haskell 编译器部分和低级代码生成之间的接口。Cmm 作为一种语言,在设计和功能集方面与 LLVM 相当相似(例如,两者都使用 i32 等位类型...)。但是,语法却大不相同,Cmm 看起来有点像 C,而 LLVM 看起来像汇编。这两种语言的相似性并不令人惊讶,因为它们都位于编译器管道的同一点,而且 Cmm 大部分是 C-- 语言的子集。C-- 是一种由 GHC 主要开发人员之一(Simon Peyton Jones)和其他人设计的一种语言,旨在充当编译器编写人员的目标通用 IR,非常像 LLVM。(C-- 的研究重点与 LLVM 相差很大,C-- 的设计旨在尝试解决在通用语言中支持垃圾收集和异常等高级语言特性的问题,而没有任何开销。LLVM 似乎专注于支持对通用语言的积极优化)。但是,C-- 项目从未像 LLVM 一样起飞,因此 Cmm 现在仅作为 GHC 后端的一个很好的 IR。
LLVM 后端位于 Cmm 之后,因此它的工作是从 Cmm 编译到 LLVM 汇编代码。由于这两种语言非常相似,因此这主要是一件简单的事情。
新的调用约定
但是,在编写后端时,有一个主要挑战是 LLVM 没有提供正确实现 Haskell 所需的功能,因此我需要扩展 LLVM。这个扩展是我在文章开头提到的新的调用约定,为了解释它为什么是必要的,我们将非常简要地了解 GHC 使用的 Haskell 执行模型。GHC 定义了一个抽象机器来实现 Haskell 代码的执行模型。这被称为 'STG 机器'(或无脊椎无标签 G 机器),它的工作是评估 GHC 使用的最终函数式 IR,即 STG。STG 机器由三个主要部分组成,寄存器、堆栈和堆。对于这个堆栈,GHC 没有使用标准的 C 堆栈,而是实现了它自己的堆栈。但是,我们关注的是寄存器的实现方式。最简单的方法是将它们全部存储在内存中作为结构,事实上 GHC 支持这种方法(它被称为 '未注册模式',用于更轻松地移植 GHC)。但是,由于访问频率很高,实现它们的一种效率更高的方式是将它们映射到真实的硬件寄存器上,这大约将典型 Haskell 程序的运行时减少了一半。因此,GHC 就是这样做的,尽管有太多 STG 机器寄存器需要映射到真实的寄存器上,它仍然必须将其中一些寄存器存储在内存中。
但是,这对 LLVM 后端来说是一个问题,因为它无法控制寄存器分配。我们仍然可以通过仅支持 '未注册模式' 来创建一个可用的后端,但这并不实用,因为性能很差。此外,我们不仅仅关注性能,与其他后端的兼容性也是一个主要问题。我们需要支持与它们使用的相同的寄存器映射,以便由 LLVM 编译的 Haskell 代码能够与由其他后端编译的代码链接。让我们快速看一下其他后端如何实现这种寄存器映射。
对于原生代码生成器来说,这很简单,因为它完全控制着寄存器分配。那么 C 后端呢?通常,这对 C 来说也是一个问题,因为它不提供对寄存器分配的控制。值得庆幸的是,GCC 提供了一个扩展,'全局寄存器变量',它允许您将一个全局变量始终驻留在特定的硬件寄存器中。GCC 通过从其寄存器分配器使用的已知寄存器列表中删除指定的寄存器来实现此功能。
因此,LLVM 的解决方案是一个新的调用约定,但它如何工作呢?嗯,调用约定将参数传递到 GHC 期望找到 STG 机器寄存器的硬件寄存器中。因此,在进入任何函数时,它们都位于正确的位置。与 NCG 或 C 后端不同,这不会专门保留寄存器,因此在函数中间,我们无法保证 STG 机器寄存器仍然位于硬件寄存器中,它们可能已经被溢出到堆栈中。这没关系,事实上这是一种改进。它允许 LLVM 生成最有效的寄存器分配,拥有比其他后端更多的寄存器和灵活性,同时仍然保持与它们的兼容性,因为在任何函数进入时,STG 机器寄存器都保证位于正确的硬件寄存器中。
后端评估
开始的两个基准测试让您了解了 LLVM 可以为 GHC 带来的性能改进。但是,它在整体上的表现如何?我目前测试这一点的最佳方法是使用 GHC 中包含的名为 'nofib' 的基准测试套件。目前,该套件将原生代码生成器排在第一位,LLVM 代码生成器紧随其后,运行时间慢了 3%,C 代码生成器排在最后,慢了 6%。但是,LLVM 代码生成器的LLVM 代码生成器的另一个巨大优势是其更小的体积和更简单的代码库。NCG 代码量约为 20,500 行,C 后端约为 5,300 行,而 LLVM 后端约为 3,100 行。对于 C 后端,大约 2,000 行代码是 Perl 代码,用于对 GCC 生成的汇编进行后处理,这些代码脆弱且复杂,充满了正则表达式。对于 LLVM 后端,大约 1,200 行代码是一个用于生成和打印 LLVM 汇编的库,因此复杂的代码生成代码只有大约 1,800 行。
后端问题
目前我所知,LLVM 后端存在一个主要问题,即它无法实现 GHC 使用的一种名为“TABLES_NEXT_TO_CODE” (TNTC) 的优化。对于函数,GHC 需要与它们关联一些元数据,称为信息表。此表包含运行时系统使用的有关函数的信息。如果没有 TNTC 优化,则通过让信息表包含指向函数的指针来完成表和函数的链接。使用 TNTC 优化,代码和数据将被布局,以便信息表驻留在函数之前。这允许从同一个指针访问函数及其信息表,这加快了函数访问速度(一次指针查找而不是两次),并减小了信息表的大小。

其他两个后端如何处理这个问题与 STG 机器寄存器类似。NCG 可以毫无问题地实现这一点,而 C 后端无法用纯 C 实现这一点。然而,这次没有 GCC 扩展能够实现优化,它只能诉诸于对 GCC 生成的汇编代码进行后处理。对于 LLVM,我们遇到了与 C 后端相同的问题,LLVM 没有提供像我们需要的这样显式地布局对象文件中的代码和数据的方法。这种优化相当重要,在启用时可以将运行时间减少大约 5%,因此我希望将来通过向 LLVM 添加对它的支持或通过像 C 后端那样对汇编进行后处理来解决它。
LLVM 的成功?
当我要求将 GHC 调用约定包含在 LLVM 中时,他们向我索要了报酬,一篇博客文章,就是这篇。所以,我问克里斯他觉得我应该写些什么。为了确保我完全履行了诺言,只剩下一个点需要说明。> [Chris Lattner]: Talking about what you think is good and what you think should be improved in LLVM would also be great. :)
我希望看到 LLVM 获得实现 GHC 后端中 TNTC 优化的必要功能。如果 LLVM 在 Sparc 上得到更好的支持,那也很棒,因为 GHC 在这个平台上运行良好,而 LLVM 却没有。至于什么是好的?当你查看 GHC LLVM 后端时,它实现了与现有后端非常接近或更好的性能,这些后端已经存在多年,同时代码库更小、更简单。我认为你也可以从 LLVM 类型系统中获得很多好处,它确实帮助我们捕获了后端中迄今为止修复的大多数错误。最后是出色的文档。这是我真正欣赏的东西,而很多项目却缺乏这一点。
未来
自从 2009 年底完成我的论文以来,我一直没有能够在 LLVM 后端上完成很多工作。然而,我很幸运地获得了在英国剑桥的微软研究院的实习机会,那里有两名主要的 GHC 开发人员(Simon Marlow 和 Simon Peyton Jones)工作。作为实习的一部分,我将尝试实现 TNTC 优化以及一般的稳定性和优化工作。后端只利用了 2.5 版本提供的功能,因此我还需要调查并更新它以使用 2.6 和 2.7 版本的新功能。还有一个 Google Summer of Code 的学生,Alp Mestanogullari,正在后端工作。他正在尝试改进后端用于与 LLVM 交互的绑定。该绑定目前通过在临时文件中生成 LLVM 汇编代码来工作。我们希望改为使用 LLVM API,因为这应该会加快编译速度,并允许我们扩展 GHC 提供的 API 以包含 LLVM 功能。如果所有这些工作都进展顺利,希望你将在下一个主要版本中看到 LLVM 成为 GHC 的默认后端 :)如果你想更详细地了解这些内容,可以在这里找到我的关于后端的论文。
- David