LLVM 3.0 中的贪婪寄存器分配
LLVM 有两个新的寄存器分配器:基本分配器和贪婪分配器。LLVM 3.0 发布后,默认的优化寄存器分配器将不再是线性扫描,而是新的贪婪寄存器分配器。借助其全局生存范围拆分功能,贪婪算法生成的代码比线性扫描生成的代码小 1-2%,速度快 10%。
从线性扫描中吸取的教训
自 2004 年以来,线性扫描一直是 LLVM 中的默认寄存器分配器。对于如此简单的算法来说,它的效果出奇地好。事实上,其简单的设计使得对算法进行微调变得更容易,从而对生成的代码做出细微改进。更高级的寄存器分配算法通常需要构建昂贵的數據结构,或者对生存范围保持不变做出假设。这使得在运行时对二地址指令进行交换,或者重新物化常量池加载(而不是将其溢出到堆栈)变得很困难。新的寄存器分配算法需要保持这种简单性。必须能够在算法运行时更改机器代码。
线性扫描依赖于虚拟寄存器重写器来清理寄存器分配后的代码。理论上,重写器应该只将虚拟寄存器重写为分配的物理寄存器,但它还知道许多其他技巧。当线性扫描执行某些愚蠢的操作(例如从堆栈槽位重新加载寄存器两次)时,重写器将通过重用第一个寄存器并消除第二次重新加载来清理代码。该算法是局部的,它无法清理超出单个基本块的混乱。重写器总是通过消除明显的错误来挽救局面。但这需要付出高昂的代价。它占了线性扫描编译时间的近一半,而它的大量技巧集使得代码难以维护。
新的寄存器分配器应该避免犯明显的错误,以便重写器可以专注于重写寄存器。
顾名思义,线性扫描通过按线性顺序访问生存范围来工作。它维护了一个活动列表,其中包含在函数中的当前位置处存活的生存范围,这就是它在不计算完整干扰图的情况下检测干扰的方式。活动列表是线性扫描速度的关键,但也是它最大的弱点。
当所有物理寄存器都被活动列表中的干扰生存范围阻塞时,会选择一个生存范围进行溢出。在未先进行拆分的情况下溢出的生存范围会导致重写器努力清理的混乱。我们更愿意将它们拆分成更小的部分,这些部分可能可分配,但这将需要线性扫描算法回溯。这非常昂贵,并且完整生存范围拆分对于线性扫描来说并不切实际。
基本分配器
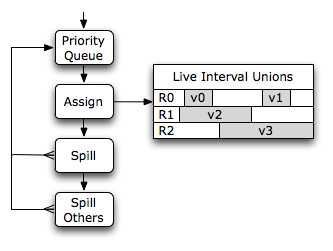
当一个生存范围无法分配到其寄存器类别中的任何物理寄存器时,它将溢出。因为生存范围按溢出权重递减的顺序分配,所以生存范围联合中的所有干扰生存范围都具有更高的溢出权重。无需寻找更好的溢出候选者。
在 CISC 架构中,溢出槽内存访问通常可以折叠到现有的指令中。在 RISC 架构中,必须插入显式的加载和存储指令。这还会在溢出代码和使用溢出生存范围的原始指令之间创建新的微小生存范围。这些新的生存范围将被放回优先级队列,并具有无限的溢出权重——它们不能再次溢出。
从技术上讲,这些具有高溢出权重的小生存范围应该首先分配,但基本分配器从不回溯。因此,可能会发生这样的情况,即这样的生存范围被已经分配的具有较小溢出权重的生存范围阻塞。在这种情况下,分配器会选择一个物理寄存器,并溢出分配到该寄存器的干扰生存范围。
基本分配器生成的代码与线性扫描的输出非常相似,并且它也依赖于虚拟寄存器重写器来清理代码以获得良好的结果。它并没有比线性扫描提供明显的优势,它主要用于测试优先级队列和生存范围联合框架。基本算法非常简单,并且提供了许多调整的机会。贪婪算法正是这样做的。
贪婪分配器

贪婪算法通过首先分配大生存范围来避免这个问题。这使得完整的寄存器类别可用于大范围,而小范围通常可以容纳在间隙中。一些函数具有太多的大生存范围,因此没有足够的空间容纳所有的小生存范围。溢出具有高溢出权重的小生存范围真的很糟糕,因此,可以从生存范围联合中驱逐已经分配的具有较小溢出权重的生存范围。被驱逐的生存范围将从其物理寄存器中取消分配,并放回优先级队列。它们有机会在其他地方分配,或者可以继续进行生存范围拆分。
当一个生存范围找不到允许其驱逐的干扰生存范围时,它不会立即溢出。如果可能,它将被拆分成更小的部分,这些部分将被放回优先级队列。这是一个非常重要的优化。一个大的生存范围可能在大多数时间都是空闲的,但在热点循环中被密集使用。通过创建一个涵盖热点循环的单独生存范围,它很有可能被分配一个寄存器。剩余的生存范围可能会溢出到它本来就处于空闲状态的循环之外。只有当拆分器决定拆分它不会有帮助时,才会将生存范围溢出。这通常发生在所有繁忙区域都被隔离之后,而剩余的生存范围只有几个复制到繁忙寄存器和从繁忙寄存器复制出来的副本。
生存范围拆分和驱逐之间的交互创建了一个逐渐细化的过程。当生存范围在繁忙区域周围拆分时,它们的溢出权重会更高。这可能允许它们驱逐在该区域中不太繁忙的旧生存范围。被驱逐的范围被拆分,等等。
逐渐拆分过程通常会在生存范围变得微小之前终止,最终结果是一组覆盖多个指令甚至多个基本块的生存范围。这意味着重写器不需要进行任何清理,事实上,贪婪算法使用了一个完全微不足道的重写器,它只有 85 行代码,而旧的重写器有 2600 行代码。
贪婪算法生成的代码几乎总是比线性扫描所能做到的更好。这通常是因为生存范围拆分能够消除循环中的溢出代码。但是,贪婪算法也有一些其他技巧。
微调
一个重要的设计目标是使算法尽可能灵活,并避免引入任意约束。可以在任何时候更改机器代码和生存范围。只需驱逐相关的生存范围,进行更改,然后将它们放回队列中。这种灵活性允许对寄存器分配器进行许多微调
- 寄存器偏好。函数参数是在由 ABI 定义的特定物理寄存器中传递的。LLVM 通过在函数调用之前和之后在物理寄存器和虚拟寄存器之间进行复制来表示这一点。寄存器分配器试图将虚拟寄存器分配到相同的物理寄存器,以便可以消除复制。线性扫描从来没有真正擅长这一点——首选的物理寄存器通常已经被之前的分配占用。当发生这种情况时,贪婪算法可以简单地驱逐之前的分配。
- 优先使用小编码。在 ARM Thumb2 和 x86-64 等架构中,某些寄存器需要更大的指令编码。贪婪算法将在分配昂贵寄存器之前从廉价寄存器中驱逐不重要的生存范围。这意味着较大的指令编码使用的频率较低,整体代码大小会减小。
- 死代码消除。重新物化等优化会导致生存范围变短,甚至完全未使用。贪婪算法将精确地重新计算生存范围,并递归地消除死代码。
- 寄存器类别膨胀。生存范围拆分会创建由更少指令使用的虚拟寄存器。这有时会消除约束,因此可以将虚拟寄存器移动到更大的寄存器类别。根据架构的不同,这可以使新生存范围可用的寄存器数量增加一倍。