ThinLTO:可扩展的增量式 LTO
ThinLTO 最初是在 2015 年的 EuroLLVM 大会上发布的,并展示了 clang 和 LLVM 中原型实现的结果。此后,该设计经过了多个 RFC 的审查,并在 LLVM(针对 gold 和 libLTO)中得以实现,并且正在进行调优。结果已经表明,对于许多基准测试而言,性能表现良好,编译时间接近于非 LTO 构建。
这篇博文涵盖了背景、设计、当前状态和使用信息。
LTO 背景和动机
LTO(链接时优化)是一种通过全程序分析和跨模块优化来提高运行时性能的方法。在编译阶段,clang 会发出 LLVM 字节码,而不是目标文件。链接器识别这些字节码文件,并在链接期间调用 LLVM 来生成构成可执行文件的最终目标文件。LLVM 实现加载所有输入字节码文件并将它们合并在一起以生成单个模块。程序间分析(IPA)和程序间优化(IPO)在此单一模块上按顺序执行。

这在实践中意味着,LTO 通常需要大量的内存(一次性保存所有 IR),并且速度非常慢。当通过 -g 启用调试信息时,IR 的大小以及由此产生的内存需求会显著增加。即使没有调试信息,对于非常大的应用程序,或者在内存受限的机器上编译时,这也是不可行的。它还会使增量构建变得效率低下,因为当任何输入源发生更改时,必须从 LTO 阶段开始重新执行所有操作。
ThinLTO 设计
ThinLTO 是一种新方法,旨在像非 LTO 构建一样进行扩展,同时保留完整 LTO 的大部分性能提升。
在 ThinLTO 中,顺序步骤非常薄且快速。这是因为,它不是加载字节码并合并单个单一模块来执行这些分析,而是利用每个模块的紧凑摘要在顺序链接步骤中进行全局分析,以及用于以后跨模块导入的函数位置索引。函数导入和其他 IPO 变换在模块在完全并行的后端进行优化时执行。
ThinLTO 全局分析启用的关键变换是函数导入,其中仅将可能内联的那些函数导入到每个模块中。这最大限度地减少了每个 ThinLTO 后端的内存开销,同时最大限度地提高了最具影响力的跨模块优化机会。因此,IPO 变换在扩展了导入函数的每个模块上执行。
ThinLTO 过程分为 3 个阶段
- 编译:生成 IR,与完整 LTO 模式相同,但扩展了模块摘要
- Thin 链接:Thin 链接器插件层,用于组合摘要并执行全局分析
- ThinLTO 后端:基于摘要的导入和优化的并行后端

默认情况下,支持 ThinLTO 的链接器(见下文)设置为在线程中启动 ThinLTO 后端。因此,第二阶段和第三阶段之间的区别对用户来说是透明的。
该过程的关键推动因素是在阶段 1 中发出的摘要。这些摘要使用字节码格式发出,但旨在能够单独加载,而无需涉及 LLVMContext 或任何其他昂贵的构建。每个全局变量和函数在模块摘要中都有一个条目。条目包含抽象描述其符号的元数据。例如,函数通过其链接类型、包含的指令数和可选的性能分析信息(PGO)进行抽象。此外,记录对另一个全局的每个引用(地址获取、直接调用)。这些信息能够在 Thin Link 阶段构建完整的引用图,并随后使用全局摘要信息进行快速分析。
当前状态
ThinLTO 目前在 gold 插件中以及从 Xcode 8 开始的 ld64 中受支持。此外,目前正在为 lld 链接器添加支持。clang 的 3.9 版本将使用 -flto=thin 命令行选项提供 ThinLTO。
虽然调优仍在进行中,但 ThinLTO 与 LTO 相比已经表现出色,在许多情况下与性能改进相匹配。在一些情况下,ThinLTO 甚至超过了完整 LTO,这很可能是因为 ThinLTO 较高的可扩展性允许使用更激进的后端优化管道(类似于非 LTO 构建)。
以下结果是在 8 核 2.6GHz 英特尔至强 E5-2689 上针对 C/C++ SPEC cpu2006 基准测试收集的。每个基准测试单独运行三次,结果显示为三次运行的平均值。
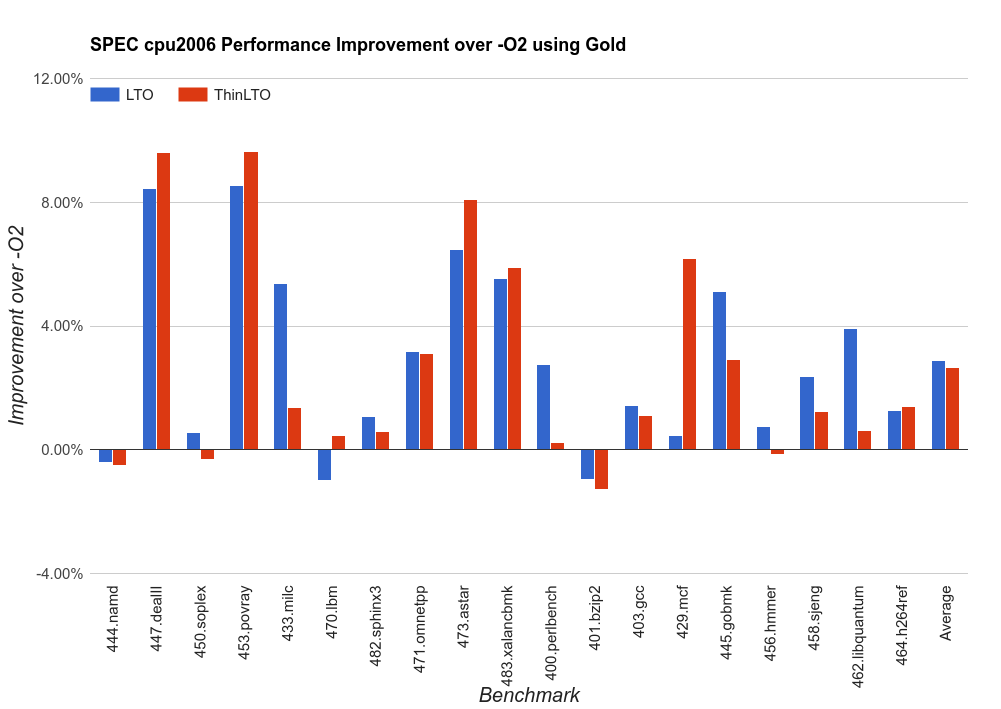
最重要的是,由于 ThinLTO 的可扩展设计,这种性能是在构建时间保持在非 LTO 构建规模内的前提下实现的。以下构建时间是在 20 核 2.8GHz 英特尔至强 CPU E5-2680 v2 上收集的,运行 Linux 并使用 gold 链接器。结果是针对从干净构建目录构建 clang(ninja clang)的端到端构建,因此它包括所有编译步骤以及 llvm-tblgen 和 clang-tblgen 等中间二进制文件的链接。

发行版构建显示了 ThinLTO 构建时间与非 LTO 构建非常接近。添加 -gline-tables-only 会增加非常小的开销,ThinLTO 再次类似于常规的非 LTO 构建。但是,在使用完整的调试信息时,ThinLTO 仍然比非 LTO 构建慢一些,这是因为导入过程中的额外开销。预计正在进行的对调试元数据表示和处理的改进将继续减少这种开销。在所有情况下,完整 LTO 实际上都要慢得多。
在内存消耗方面,改进是显著的。在过去的两年中,FullLTO 得到了显著改进,如下面的图表所示,但我们的测量表明 ThinLTO 保持着巨大的优势。

使用信息
要使用 ThinLTO,只需将 -flto=thin 选项添加到编译和链接中。例如
% clang -flto=thin -O2 file1.c file2.c -c% clang -flto=thin -O2 file1.o file2.o -o a.out
如前所述,默认情况下,链接器将并行启动 ThinLTO 后端线程,并将生成的本机目标文件传递回链接器以进行最终本机链接。因此,使用模型与非 LTO 相同。与常规 LTO 类似,对于 Linux,这需要使用 配置为启用插件的 gold 链接器 或从 Xcode 8 开始的 ld64。
分布式构建支持
要利用分布式构建系统,可以将并行 ThinLTO 后端分别作为单独的进程启动。为了支持这一点,gold 插件提供了一个 thinlto_index_only 选项,该选项会导致链接在创建组合索引并执行全局分析后退出。
此外,在此模式下
- 它不使用单一的组合索引,而是为每个后端编写一个单独的索引文件,其中包含组合索引的必要部分,用于记录导入以及任何其他应在后端执行的基于全局摘要的优化决策。
- 可选地,将每个模块将从中导入的字节码文件的纯文本列表输出,以帮助分布式构建文件分段(thinlto-emit-imports-files 插件选项)。
可以通过在字节码上调用 clang 并通过选项提供其索引来启动后端。最后,将生成的本机目标文件链接以生成最终二进制文件。例如
% clang -flto=thin -O2 file1.c file2.c -c
% clang -flto=thin -O2 file1.o file2.o -Wl,-plugin-opt,-thinlto-index-only
% clang -O2 -o file1.native.o -x ir file1.o -c -fthinlto-index=./file1.o.thinlto.bc
% clang -O2 -o file2.native.o -x ir file2.o -c -fthinlto-index=./file2.o.thinlto.bc
% clang file1.native.o file2.native.o -o a.out
增量式 ThinLTO 支持
使用完整 LTO,只有初始编译步骤可以增量执行。如果任何输入发生更改,则必须重新执行昂贵的顺序 IPA/IPO 步骤。
使用 ThinLTO,如果任何输入发生更改,则必须重新执行顺序 Thin Link 步骤,但是,如前所述,该步骤很小且很快,并且不涉及加载任何模块。并且,仅当以下情况发生时,才必须重新执行任何特定的 ThinLTO 后端
- 相应的(主)模块的字节码发生更改
- 导入到模块或从模块导出的列表发生更改
- 从其导入的任何模块的字节码发生更改
- 影响主模块或其导入的任何内容的任何全局分析结果发生更改。
对于单机构建,其中线程由链接器启动,可以通过在应用基于全局摘要的优化(如导入)后缓存模块来实现增量构建,使用上述信息的哈希值作为键。libLTO 的 ThinLTO 处理中已经支持这种缓存,它由 ld64 使用。要启用它,链接步骤需要传递一个额外的标志:-Wl,-cache_path_lto,/path/to/cache
对于分布式构建,项目 2-4 中的信息都序列化到单独的索引文件中。因此,构建系统可以将输入字节码文件的内容(主模块的字节码以及所有从其导入的字节码)以及组合索引与之前构建的内容进行比较,以确定是否必须重新执行特定的 ThinLTO 后端。为了使此过程更有效,在编译阶段发出字节码文件的内容时对其进行哈希处理,并将结果存储在字节码文件中本身,以便可以在 Thin Link 步骤期间查询缓存,而无需读取 IR。
下面的图表说明了 clang 在三种不同情况下的完整构建时间
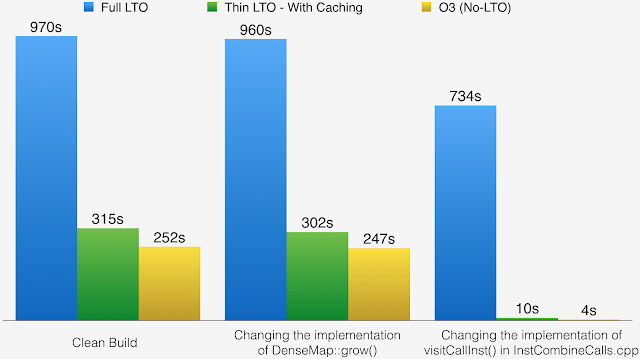
下面的图表说明了 clang 在三种不同情况下的完整构建时间
- 干净构建之后的完整链接。
- 开发人员修复了 DenseMap::grow() 的实现。这是项目中广泛使用的标头,它强制重新构建大量文件。
- 开发人员修复了 InstCombineCalls.cpp 中 visitCallInst() 的实现。这是一个实现文件,增量构建应该很快。

这些结果说明了完整 LTO 如何不利于增量构建,并展示了 ThinLTO 如何提供与非 LTO 构建非常接近的增量链接时间。