为 ARM 处理器生成可重定位代码
摘要
通过升级 LLVM 编译器,我们解决了 LLVM 和 GCC 都无法为 Cortex M 控制器创建正确的与位置无关代码的问题,该代码在 Flash 内存中运行而不是在 RAM 中运行。现在,程序的二进制映像可以被闪存到任意地址并从该地址运行,而无需移动到另一个位置。
更新微控制器的“固件”是一个危险的过程。以前,更新期间的任何硬件故障都可能导致设备变砖。如今,设备通常有自己的引导加载程序,允许您在设备的功能丢失之前重新启动更新。在更新完成之前,设备将无法工作。最巧妙的更新方式是使用两个独立的“固件”区域——主区域和备用区域。在下图中,它们分别用红色和蓝色标记。最初,红色区域处于活动状态,而更新将加载到蓝色区域。这样一来,引导失败就不是什么大问题。红色区域仍然会运行所有内容。如果更新成功,蓝色区域将变为活动状态。下一个更新将加载到红色区域,依此类推。每次更新都会导致这种切换。

不幸的是,对于 Cortex M 系统,这种方法不能直接使用。程序与绝对地址绑定,不能在任意位置运行。本文解释了原因,以及我们如何通过修改 LLVM 编译器来使程序可重定位。
介绍
阅读过文档的人可能会说,编译器已经有了创建可重定位代码的选项。在 LLVM 的情况下,它是 -fropi、-frwpi 和其他选项。这也是我们开始测试的地方。事实证明,这些选项对于程序完全加载到 RAM 的系统非常方便。在这种情况下,常量(位于代码中)和变量(位于数据段中)都位于同一个大段中。因此,它可以很容易地在 RAM 中移动。
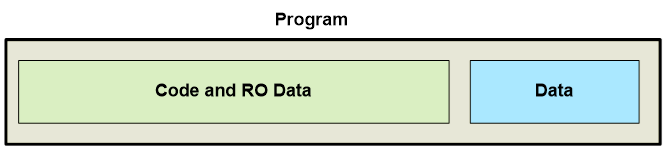
对于 Cortex M 控制器来说,情况并非如此。它们的代码位于大容量 ROM 中,而数据存储在小容量 RAM 中。此外,这些实体位于 Flash/RAM 的不同部分。

使用这些选项会导致数据与程序偏移相同……但 RAM 比 ROM 小得多!因此,数据超出了允许的范围。

或者,在 RAM 中创建指向代码常量的巨大指针表。此表的尺寸显著提高了 RAM 使用量。因此,有时 Cortex M 控制器提供的 RAM 量不够。

很明显,对于目标平台(Cortex M 控制器),我们必须对编译器进行修改。
基本原理
为了保持一致性,让我们从基础知识开始。在计算机中,数据和代码位于全局内存中。在给定的体系结构中(与几乎所有其他体系结构一样),使用了线性地址空间,因此对象的地址可以通过一个数字来定义。为了对内存单元执行特定操作,处理器必须知道该单元的地址。
这就是问题变得复杂的地方。最大指令和地址大小都是 32 位。因此,您不能只是将 32 位地址放置到指令中——它必须有足够的空间来容纳指令的代码。其中一个解决方案是使用相对寻址。在运行时,程序计数器寄存器包含当前指令的地址。这是一个完整的 32 位寄存器,其内容由硬件控制。通过读取它,程序可以知道自己在 Flash 中的位置。指令中有一些偏移量,因此当前位置附近的相当一部分地址变得可用。例如,如果您需要调用一个位于当前运行函数附近的函数,处理器将执行一个带有单个指令的跳转。
在这里,函数 MyFunc 位于调用位置附近
bl MyFunc
...
.type MyFunc,%function
MyFunc:
...
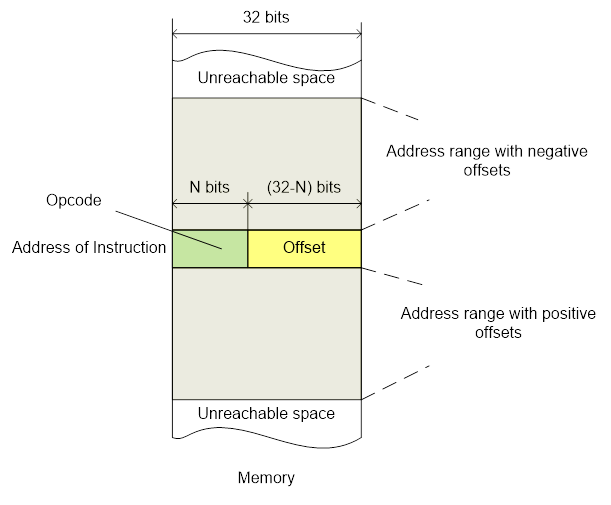
但是,这只是一个部分解决方案,因为并非所有跳转都是相对的,有些是绝对的。不过有一个解决方案。我们将绝对地址直接放入 Flash 中的代码中,靠近使用该地址的地方。然后以类似的方式,我们对该地址执行 PC 相对加载到寄存器中,并使用下一条命令对寄存器相对加载值本身。更高级的方法是使用 movw、movt 指令对。目标 32 位地址被分成两半,然后分两步加载到寄存器中。虽然这意味着使用两条命令,但它可以节省额外的寻址。
将 global_result_data7 地址的内容加载到 r0 寄存器中
movw r0, :lower16:global_result_data7
movt r0, :upper16:global_result_data7
ldr r0, [r0]
让我们仔细看看寄存器加载过程,其中变量 global_result_data7 的地址为 0x12345678

现在,当我们弄清楚处理器如何操作地址时,是时候解释它们从何而来了。Flash/RAM(有一些例外)是统一的,这意味着地址为 0x1000 的函数也可以位于 0x2000 处,唯一的条件是地址必须已知。链接器负责分配地址。它接收程序的所有对象作为输入,并根据附加的配置文件为它们分配空间。这样,每个对象都获得了自己的地址,这些地址被写下来到使用这些函数的地方。此外,值得注意的是,Flash/RAM 不必从零地址开始,起始地址 0x08000000 也相当常见。此值必须添加到所有全局地址中。
问题定义
因此,我们有一个二进制映像,适合加载到设备的 Flash/RAM 中。当我们从链接时定义的初始地址写入它,然后运行它时,程序正常工作。所有数据都位于预期位置,所有调用的地址都包含必要的函数,等等。有人可能会问,如果我们从另一个地址加载映像会怎样?首先想到的是,一切都将崩溃。程序将从地址 0x1000 访问单元值,但实际上它将位于完全不同的位置。但是,让我们想象一个只包含一个指令的基本程序——无限循环。显然,这样的程序是可重定位的:因为这样短的跳转是 PC 相对执行的,所以它会自动“调整”到它的新位置。此外,如果程序中的所有跳转/调用都是相对的,那么它可以非常大、很复杂;至少所有函数都被正确调用。直到程序尝试使用全局地址,其值相对于预期偏移才出现问题。
现在是时候问一个问题了:这是一个问题吗?程序绑定到绝对地址有什么问题?程序能够从任意地址运行有什么好处?有人可能会说,如果它具有成本效益,那么这是一件好事。但它可能具有更具体的用途。例如,设备可以从外部接收一段代码,这将扩展现有程序的功能,并将其作为当前代码的补充进行加载。如果这段代码能够与它在 Flash 中的位置无关地运行,那就非常方便了。最后,还可能发布完整的固件更新。它也必须位于 Flash 中的某个地方,然后才能控制设备。值得注意的是,我们不知道它最终会出现在哪里,因此能够从任意地址运行是一个必要条件。
因此,实现可重定位代码的任务值得研究。应该指出的是,在大型系统中,这通过使用虚拟内存来解决。程序中使用的逻辑地址被静默映射到物理地址,因此没有问题。但是,这是一个完全不同的技术水平。我们专注于 Cortex-M,没有 MMU 模块。这就是为什么在我们的案例中,我们必须通过添加程序的内存偏移值来“调整”全局地址。因为所有地址计算都归结为偏移量和指针的差异,因此无需进行其他更改。
这提出了一个新的任务——检索程序在 Flash 中相对于链接时定义的初始地址的偏移值。例如,可以使用以下技巧。全局地址保持不变,而 PC 值不同。您在从“正常地址”和“硬编码”地址运行时获得全局地址与 PC 之间的差异并将其插入到程序中。当从偏移地址运行时,此差异不同,计算它发生了多少变化会给出偏移值。但是,正如稍后将展示的那样,有一种更直接的方法可以获得偏移值,因此现在,让我们假设偏移值已知。
实现(初始方法)
因此,处理器将全局地址加载到寄存器中。当您使用汇编器时,您只需要在它之后插入一条特定指令,这将将偏移值添加到结果中。
DoOperation 函数接收全局地址 global_operation5,该地址由 r9 寄存器值修改
movw r0, :lower16:global_operation5
movt r0, :upper16:global_operation5
add r0, r9
bl DoOperation
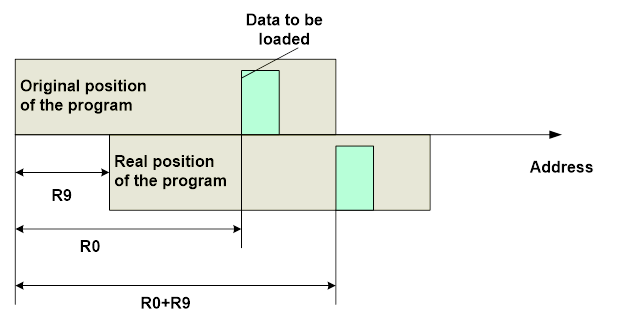
为此,我们必须保留寄存器以永久存储此值。当然,我们可以每次从 RAM 中加载它,但预期的损失(ROM 体积和处理器周期)比失去一个寄存器更高。但是,如果我们用 C 编码,该怎么办?显然,整个方案只有在我们不必修改源代码时才有意义。在某些地方进行一些特殊的操作是一回事,但不能进行重大更改。幸运的是,编译器只需进行少量修改即可处理给定任务。
问题是,编译器完全清楚自己在做什么。我们使用 LLVM,因为我们在修改此编译器方面拥有丰富的经验,因此,我们将在下面仅讨论 LLVM。LLVM 具有用于独立地址空间的机制,允许我们将属性绑定到指针,该属性定义数据位置。在我们的案例中,我们假设只有 ROM 内容被移动,而 RAM 地址保持不变。在这种情况下,我们为常量全局对象(函数、常量数据、字符串文字——所有进入只读内存的内容)设置了一个单独的地址空间。
在这里,我们为常量数据设置了一个单独的地址空间,并将它映射到全局对象
llvm::Optional<LangAS> ARMTargetInfo::getConstantAddressSpace() const {
return getLangASFromTargetAS(REL_ROM_AS);
}
LangAS getGlobalVarAddressSpace(CodeGenModule &CGM, const VarDecl *D) const override {
if (D && CGM.isTypeConstant(D->getType(), false)) {
auto ConstAS = CGM.getTarget().getConstantAddressSpace();
assert(ConstAS && "No const AddressSpace");
return ConstAS.getValue();
}
return TargetCodeGenInfo::getGlobalVarAddressSpace(CGM, D);
}
此属性在整个编译过程中“存在于”类型中;在对象地址加载期间,有一种方法可以识别 ROM 分配并插入用于偏移的必要指令。
静态初始化问题
不幸的是,有一种情况是我们无法用这种方法处理。我们有一个全局指针数组,它用 ROM 和 RAM 地址的混合进行初始化。
数组 arr 包含两个地址:一个用于 ROM,另一个用于 RAM
int ro;
const int rw;
const int *arr[] = { &ro, &rw };
此初始化是静态执行的,这意味着链接器分配了 Flash 并用表示为符号地址的数字填充它。
数组 arr 的静态初始化
.type arr,%object
.section .rodata,"a",%progbits
arr:
.long ro
.long rw
.size arr, 8
它还不知道未来的偏移值,因此它什么也做不了。应该指出的是,链接器有多种类型和大小,它们可以具有各种高级功能,但当时,我们坚持使用简单的二进制映像。因此,我们有一个数字数组。但我们也不能在运行时做任何事情,因为我们不再知道哪些地址来自 ROM,哪些来自 RAM。那么,我们的整个想法就这样泡汤了吗?
本质上,存在一种非常昂贵但用途广泛的解决方案。如果我们知道 RAM 和 ROM 地址范围,我们可以将整个寻址过程通过一个特殊函数发送,该函数根据地址值定义地址的来源,并在必要时对其进行修改。但是,它所需的开销非常大。在这种情况下,该解决方案纯粹是理论上的,显然除了某些个别情况外,不适用于现实世界的应用。
实现 (新方法)
我们希望我们在固件加载期间修改地址。当然,这需要我们更改将映像加载到闪存的程序,以及提供有关映像本身的附加信息,但这个想法实际上听起来很合理。如上所述,从任何加载地址运行的能力是以代码大小略微增加和性能略微下降为代价的。如果我们直接在二进制映像中修复所有瓶颈,则可以在没有上述性能/效率损失的情况下实现可重定位性。存在潜在的缺陷,但这个想法值得尝试。
第一种方法虽然粗糙,但很有希望。我们想知道如果我们让两个固件变体从不同的地址加载并进行比较会怎么样。只有地址应该改变,所以我们会看到所有需要修改的地方。然而,事实证明,差异远不止这些。其中一些可能被忽略,因为它们与我们的任务无关,但我们不能保证我们总是能够区分有效的问题和伪影。最终,整个方法本身对于严肃的应用来说听起来太天真了。
考虑到以上内容,很明显我们必须至少改变一些用于全局指针初始化的地址。为了简便起见,我们假设在代码生成期间创建了一个中间汇编文件,并且我们可以干预这个过程。然后出现了一个新想法。每次编译器使用全局地址进行初始化时,我们都可以看到它使用了哪个地址空间,如果它是来自 ROM 的,我们可以在它前面放一个标签。
我们在 ROM 地址初始化之前放置了标记。
mainMenu:
Reloc2:
.long mainMenuEntriesC
.long mainMenuEntriesM
Reloc3:
.long mainMenuEntriesC+8
在模块末尾,我们添加了一个带有特殊名称的部分,并将所有这些标签放入其中。
标签被放入 reloc_patch 部分
.section .reloc_patch,"aw",%progbits
.globl _Reloc_3877008883_
_Reloc_3877008883_:
.long Reloc1
.long Reloc2
.long Reloc3
在链接器脚本中,我们将此部分定义为 KEEP,以便它保持完整,因为显然没有使用它的数据。稍后,当可执行文件被链接时,所有添加的部分将被合并在一起,标签将获得与二进制映像地址相对应的特定值。这里关键的一点是,这些地址等于输出文件中的偏移量。因此,我们可以找到需要更改的地方。需要注意的是,如果初始化数据位于 RAM 中,它们的初始化将位于 ROM 中,并具有已知的偏移量。因此,我们需要两个部分:一个用于 ROM,另一个用于 RAM 数据。第一个部分按上述方式处理,而对于第二个部分的地址,我们必须减去初始 RAM 地址并添加链接器脚本文件中定义的初始化块偏移量。
然后我们编写了一个小型实用程序,从 ELF 表示中恢复我们的部分,并获取全局地址的偏移量列表。
需要注意的是,有一种简单的方法可以使用标准方法获取重定位表,即链接器在设置 –q 操作码时在 ELF 中创建部分。这些表包含我们使用上述方法检索的所有数据,也可以用于我们的目的。但是,它们太大,而我们旨在减少内存使用。此外,我们只使用它们的小部分;因此,我们将不得不处理表重定位解析问题。一方面,我们通过保留编译器原样来节省精力,另一方面,它会带来另一个问题。因此,我们决定采用上述方法。
方法的开发
这足以在加载时修改固件,但我们更进一步。我们定义了一组简单的命令,例如:
'D' [数量] {数据} - 从输入流中写入以下数量的字节
'A' [数量] - 将数量解释为地址,向它们添加一个特定值,并将它们打印到输出
向输出流发送四个字节并更正两个地址
'D' 0x4 0x62 0x54 0x86 0x12 'A' 0x2 0x00001000 0x00001008
如果偏移量为 0x4000,则结果将如下所示(为了清晰起见,我们不会将数字分解为字节)
0x62 0x54 0x86 0x12 0x00005000 0x00005008
然后我们将初始二进制映像转换为此类命令的流。所有数据(直到需要修改的第一个地址)都被跳过而没有更改,然后是修改一个或两个地址的命令,然后是一些数据,依此类推,直到文件结束。这样,地址校正的信息就被嵌入到二进制映像中。一方面,结果文件不再是适合引导刷写的固件。但是,我们能够在流模式下“动态”地处理它,因为我们接收到了它,使用了一个小缓冲区。因此,我们必须稍微修改加载程序,以根据接收到的命令更改地址,而不是仅仅将输入流写入板载闪存/RAM。此外,我们创建了一个额外的实用程序,它接受这样的文件和一个起始地址作为输入,然后创建一个固件。
我们更进一步。如上所述,一些地址被“硬编码”到 movw、movt 指令对中。编译器可以识别哪些地址对应于 ROM 地址加载,在这些地址处放置标签,并为它们创建另一个部分。此外,我们添加了一个命令,该命令从流中选择两个字,将它们解释为加载指令对,检索地址,更改它,然后放回。因此,运行时的额外步骤变得不再需要。除此之外,我们获得了轻松修改程序的能力(例如,更改版本号等)。
这也允许我们根据需要向程序提供偏移量值。为此,我们创建了一个带有特殊名称的函数,该函数将常量值写入 RAM 单元。在代码中,此函数以两个 movw、movt 对开头 - 第一个是加载 RAM 单元地址,第二个是用于常量本身。
在 RAM 单元和 r9 寄存器中检索偏移量
int rel_code = 0;
int set_rel_code() {
rel_code = 0x12345678;
return rel_code;
}
void __attribute__((section(".text_init"))) Reset_Handler(void) {
set_rel_code();
asm(“mov r9, r0”);
...
}
我们添加了另一个流命令,该命令没有将偏移量添加到加载指令对中硬编码的值中,但实际上将该值更改为给定的值。结果,该函数将偏移量值本身放入 RAM 中,并且在函数调用之后,此值可用。总的来说,这开辟了相当广泛的可能性,因此额外的困难看起来是合理的。
当前限制
毫无疑问,需要使用中间汇编文件是实现的一个缺陷。可以忽略它,因为很难说它到底会影响什么。也许,我们将在未来版本中通过直接在编译器内部表示中创建标签来摆脱它。用于检索二进制映像位移的服务部分实际上占用内存空间,这也不是什么好事。但是,只要在加载期间没有错误,我们就可以为它们提供闪存/RAM 缺失的虚构地址。
结论
LLVM 编译器被修改为生成可以在加载到闪存之前绑定到任何地址的二进制代码,而无需使用额外的源代码或开发环境。所有必要的信息都包含在二进制代码中。