GSoC 2024:LLVM-IR 编译的统计分析
欢迎!我叫 Andrew,我在 2024 年的 Google Summer of Code 项目中为 LLVM 做出了贡献。我的项目名为 LLVM-IR 编译的统计分析。该项目的目的是分析优化流水线中各阶段的耗时情况。通常,流水线中某个阶段所占时间的百分比出现巨大差异被认为是异常情况。
背景
原则上,LLVM IR 位码文件(或模块)包含决定编译器优化流水线行为的 IR 特征。通过改变这些特征,优化流水线(opt)可以显著增加编译时间,或略微增加编译时间。更具体地说,优化在更短或更长的时间内完成;用户可能等待微秒或几分钟。LLVM 编译器开发人员不断编辑流水线,因此这些优化的性能可能会因编译器版本而异(有时差异很大)。
拥有一个像 ComPile 这样的大型 IR 数据集,可以让我们在各种 IR 样本上测试 LLVM 编译流水线。此样本的规模足以确定异常的 IR 模块。通过使用正在添加到 LLVM IR 数据集实用程序仓库 的实用程序来识别和检查这些文件,可以确定意外编译时间的根源。然后,开发人员可以相应地修改和改进编译流水线。
工作总结
在 PR37 中添加的实用程序旨在将每个 IR 模块写入与编程语言相对应的 tar 文件。写入 tar 文件的每个文件都由其在 HF 数据集中的位置索引。这使得能够轻松识别用于 shell 中数据提取和分析的工具,特别是 clang。创建 tar 文件可以节省磁盘空间,而不是将 HF 数据集下载到磁盘,并且可以编写不依赖 Python 解释器来加载数据集以进行访问的代码。
来自 PR36 的 Makefile 负责执行数据收集。这些数据包括文本段大小、编译期间的用户 CPU 指令计数(类似于时间)、来自 LLVM 阶段 print<func-properties> 的 IR 特征计数,以及最大相对时间阶段名称和百分比计数。数据可以在并行或串行模式下提取,并存储在 CSV 文件中。
Makefile 中一个重要的数据收集命令是 clang -w -c -ftime-report $(lang)/bc_files/file$@.bc -o /dev/null。该命令的输出很大,但我们感兴趣的是第一个 Pass execution timing report(阶段执行计时报告)
===-------------------------------------------------------------------------===
Pass execution timing report
===-------------------------------------------------------------------------===
Total Execution Time: 2.2547 seconds (2.2552 wall clock)
---User Time--- --System Time-- --User+System-- ---Wall Time--- --- Name ---
2.1722 ( 96.5%) 0.0019 ( 47.5%) 2.1741 ( 96.4%) 2.1745 ( 96.4%) VerifierPass
0.0726 ( 3.2%) 0.0000 ( 0.0%) 0.0726 ( 3.2%) 0.0726 ( 3.2%) AlwaysInlinerPass
0.0042 ( 0.2%) 0.0015 ( 39.2%) 0.0058 ( 0.3%) 0.0058 ( 0.3%) AnnotationRemarksPass
0.0014 ( 0.1%) 0.0005 ( 13.3%) 0.0019 ( 0.1%) 0.0020 ( 0.1%) EntryExitInstrumenterPass
0.0003 ( 0.0%) 0.0000 ( 0.0%) 0.0003 ( 0.0%) 0.0003 ( 0.0%) CoroConditionalWrapper
2.2507 (100.0%) 0.0039 (100.0%) 2.2547 (100.0%) 2.2552 (100.0%) Total
用户可以使用针对 .json 文件的分析工具直观地查看这些阶段的分布情况。给定位码文件的 .json 文件可以通过 clang -c -ftime-trace <file> 获取。
此输出的视觉化可以过滤到我们感兴趣的阶段,如下面的图像所示

CoroConditionalWrapper 阶段由 “Total CoroConditionalWrapper” 块表示。显然,该阶段所占时间远小于其他阶段,如阶段执行计时报告所示。但是,与将其视为时间中微不足道的百分比相比,可视化可以进一步比较每个阶段的相对时间。示例图像选择了我们感兴趣的优化阶段,但 .json 文件还提供了整个编译流水线的信息。因此,可以可视化整个流水线的执行流程。
当前状态
目前,有三个 PR 需要批准才能合并。关于其内容已经进行了持续的讨论,因此合并它们应该只需要几步。在当前状态下,使用 PR38 中的实用程序的用户应该能够轻松地复制我在 GSoC 中期演示文稿中获得的量化结果。用户也可以轻松地对 IR 文件进行异常值分析(排除 Julia IR)。一些结果包括:
C IR 文件的散点图
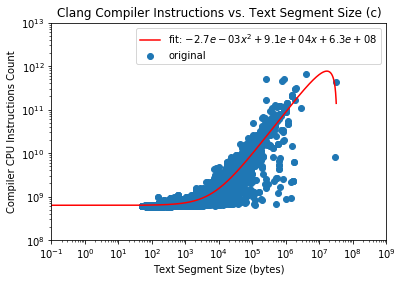
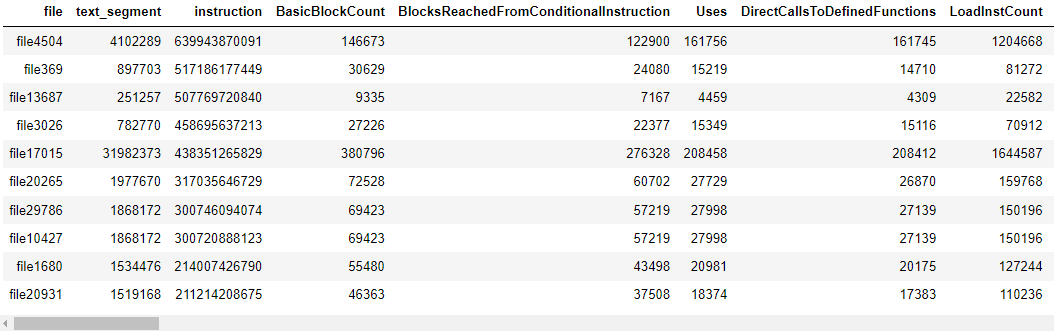
C IR 文件的异常值表
未来工作
在 PR 37 中,讨论过将 tar 文件创建合并到数据集文件写入的 Python 脚本中。这是一个我希望实现的功能,目的是通过将位码文件从内存写入 tar 文件而不是从内存写入磁盘再写入 tar 文件来加快 tar 文件创建过程。
如前所述,Julia IR 未经分析。修改脚本以包含 Julia IR 结果是可取的,以便充分利用数据集。添加用于演示用途的更多文档可以帮助澄清使用这些工具的方法。
此外,可以通过使用更先进的异常值检测方法来扩展异常值分析。CSV 文件中收集的并非所有数据都已使用,因此使用这些额外功能(特别是 print<func-properties> 阶段)可以提高异常值检测的准确性。
致谢
我要感谢我的导师 Johannes Doerfert 和 Aiden Grossman 在 GSoC 项目期间和之前对我的持续支持。此外,我要感谢 LLVM 基金会管理人员和 GSoC 管理人员的工作。