GSoC 2024:LLVM 中的 1001 个阈值
大家好!我的名字是 Shourya,我在今年夏天通过 GSoC 在 LLVM 上工作。我的项目叫做 LLVM 中的 1001 个阈值。这个项目的主要目标是研究 LLVM 中不同阈值的变化如何影响性能参数,例如编译时间、位码大小、执行时间和 LLVM 统计数据。
背景
LLVM 有很多阈值和标志来避免“代价高昂的情况”。但是,这些阈值是否有用、它们的取值是否合理,以及它们真正产生了什么影响尚不清楚。由于阈值很多,无法进行简单的穷举搜索。这方面的一个工作示例包括引入一个 C++ 类来替换硬编码的值,该类可以控制阈值,例如,可以通过命令行标志将递归限制从硬编码的“6”增加到不同的数字。因此,需要探索 LLVM 中的不同阈值,了解阈值被触发的含义,分析不同的阈值并为不同的阈值选择最佳值。
我们做了什么
这项工作提供了一个工具,可以有效地探索这些旋钮,并了解修改它们如何影响度量指标,例如编译时间、生成程序的大小,或 LLVM 发出的任何统计数据,例如“矢量化的循环数量”。(注意,目前不评估执行时间,因为输入生成器不适用于优化后的 IR,因此是未来工作的一部分。)
我们首先构建了一个 Clang 匹配器,我们为其寻找以下模式
- Const knob_name = knob_val
- Cl::init
- Enum {knob_name = knob_val}
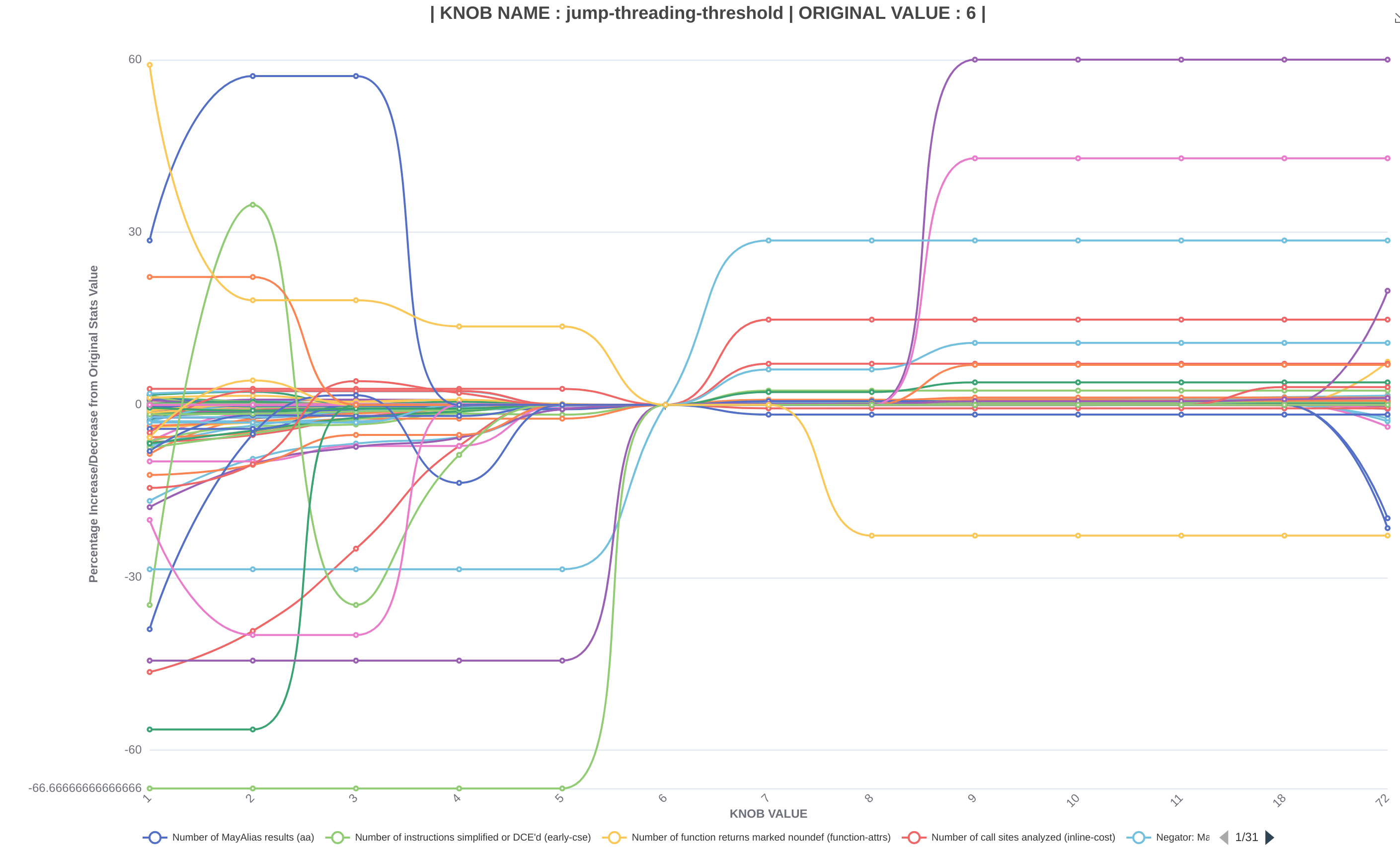
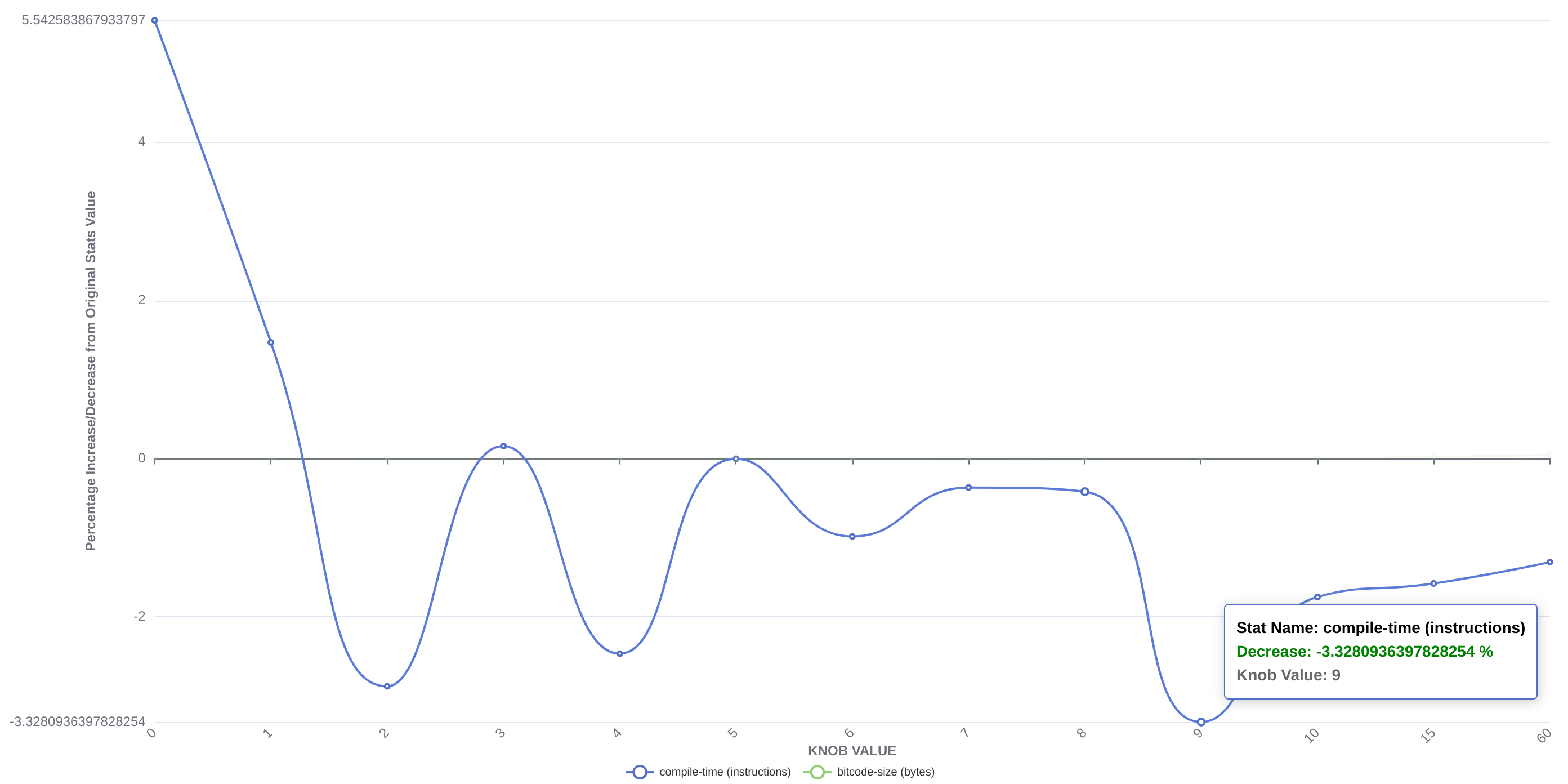
首先识别代码库中的 旋钮,然后使用自定义 Python 工具(针对 I/O 和缓存瓶颈进行了优化)并行收集不同的统计值,并将它们存储在 JSON 文件中。在手动选择有趣的旋钮后,我们迄今为止进行了三项研究,我们在这三项研究中测量了编译时间和位码大小以及各种其他统计数据,并以交互式图形的形式呈现它们。其中两项(在 10,000 和 100 个位码文件上)查看每个旋钮值的平均统计数据,而第三项(在 10,000 个位码文件上)研究了改变旋钮值对每个文件的影响。我们在这些图形中看到了一些非常有趣的模式,例如,在下述两个图形中,代表跳转线程阈值,我们可以观察到,如果增加旋钮值,则可以观察到统计数据得到改善(顶部图形)并且平均编译时间减少(底部图形)。
结果
每个文件的研究证明,不存在单个神奇的旋钮值,并且最佳值(关于编译时间或代码大小)取决于当前正在编译的文件。例如,在这里我们可以看到,不同的旋钮值(对于旋钮 licm-mssa-optimization-cap)对不同的文件提供了良好的累积编译时间改进。具体来说,大多数文件受益于旋钮值为 300,而对于第二多的文件,60 是最佳旋钮值。
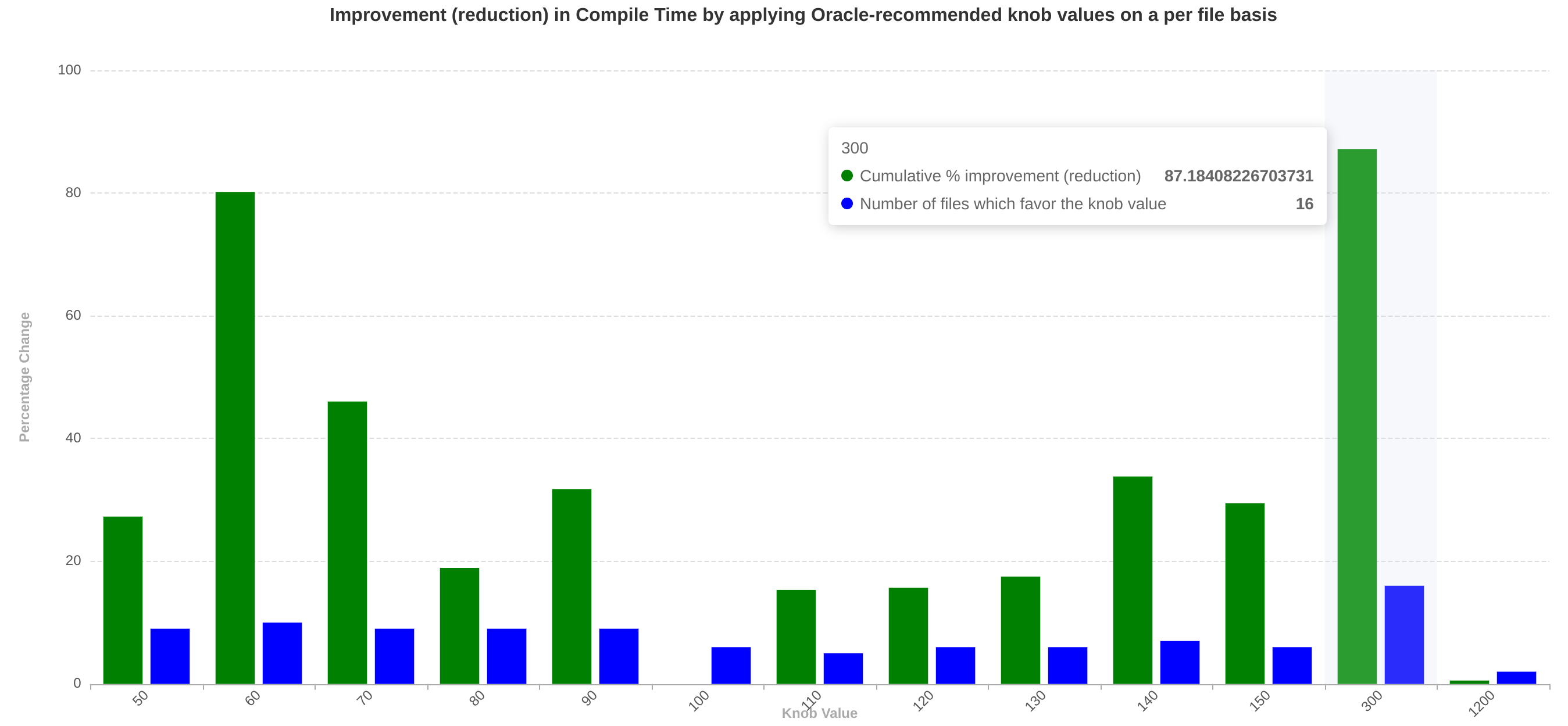
我们进一步表明,存在一个能够告知每个文件最佳旋钮值的预言机,可以显着提高累积编译时间。

在这个项目中,我们探索了 LLVM 中的各种阈值——具体来说,93 个阈值(每个阈值进行 100 个文件的测试,可以找到 这里)——使用 Clang 匹配器——并观察到这些阈值在很大程度上是针对特定文件的。这表明,不存在适用于不同场景的通用最佳值,甚至是一组值。相反,需要在 LLVM 中建立一个自适应机制,即一个预言机,可以在编译期间动态确定适当的阈值。
我们还通过利用 LLVM 传递中的特定于文件的信息,实验性地累积地改变了阈值。但是,在与导师讨论后,由于这将需要对 LLVM 代码库的其他部分进行重大更改,因此放弃了这种方法。
因此,我们还没有对不同的阈值进行分类,例如,确定特定文件类型(例如,I/O 密集型文件)的最佳阈值。尽管如此,我们提供了一个工具,可以有效地收集这些数据(LLVM 统计数据、位码大小和编译时间)并借助交互式图形以及直方图帮助可视化这些数据,这些图形和直方图检查了这些变化对每个文件的影響。此外,旋钮值和性能指标之间的相关性表进一步说明了这项研究可能对提高 LLVM 的整体性能产生的重大影响。
未来工作
早期结果表明,我们需要更好地了解旋钮值,以最大限度地实现各种目标。我们的结果将为社区提供开发适应正在编译的文件的指导式编译模型的第一步。我们还打算展示这些旋钮如何相互作用,以及同时修改多个旋钮是否会加剧益处还是不会。另一个工作领域可能是 输入生成,它将使我们能够在性能参数中收集和研究执行时间。
鸣谢
如果没有我出色的导师 Jan Hückelheim、Johannes Doerfert、LLVM 基金会管理员和 GSoC 管理员,这个项目是不可能完成的。