GSoC 2024: 重振 NewGVN
今年夏天我参加了 LLVM 编译器基础设施的 GSoC 项目。该项目的目的是改进 NewGVN 通道,使其能够取代 GVN 成为 LLVM 中主要的数值编号通道。
背景
全局值编号 (GVN) 的作用是为指令分配数值,使具有相同数值的指令等效。NewGVN 于 2016 年推出,旨在取代 GVN。现在我们来强调一下 NewGVN 比 GVN 更好的几个方面。
NewGVN 相对于 GVN 的一个关键优势是,它对循环是完整的,而 GVN 仅对无环代码是完整的。NewGVN 对循环是完整的,因为当它首次处理循环时,它假设只会执行第一个迭代,并在之后证实这些假设——这被称为乐观假设。在实践中,乐观假设等同于假设回边不可到达,因此在评估 phi 指令时,可以忽略它们携带的值。例如,在下面的示例中,%a 被乐观地评估为 0。这导致 %c 被评估为 %x,进而导致 %a.i 被评估为 0。此时,有两种可能性:要么假设是正确的,并且循环实际上只执行一次,并且到目前为止计算出的数值是正确的,要么需要重新评估循环中的指令。假设对于这个例子,NewGVN 无法证明只执行一次迭代。那么 %a 再次被评估为 0,并且所有其他寄存器也被评估为相同的值。由于乐观假设,我们能够发现 %a 是循环不变的,而且它等于 0。
define i32 @optimistic(i32 %x, i32 %y){
entry:
br label %loop
loop:
%a = phi i32 [0, %entry], [%a.i, %loop]
...
%c = xor i32 %x, %a
%a.i = sub i32 %x, %c
br i1 ..., label %loop,label %exit
exit:
ret i32 %a
}
另一方面,GVN 无法检测到这种等价性,因为它会悲观地将 %a 评估为自身,并且前面描述的评估步骤永远不会发生。
NewGVN 的另一个优势是使用 MemorySSA 对内存操作进行数值编号。它提供了内存的功能视图,其中可以修改内存的指令会生成一个新的内存版本,然后其他内存操作会使用该版本。这极大地简化了对内存操作中冗余的检测。例如,来自等效指针和内存版本的相同类型的两个加载,在本质上是等效的。
define i32 @foo(i32 %v, ptr %p) {
entry:
; 1 = MemoryDef(liveOnEntry)
store i32 %v, ptr %p, align 4
; MemoryUse(1)
%a = load i32, ptr %p, align 4
; MemoryUse(1)
%b = load i32, ptr %p, align 4
; 2 = MemoryDef(1)
call void @f(i32 %a)
; MemoryUse(2)
%c = load i32, ptr %p, align 4
%d = sub i32 %b, %c
ret i32 %d
}
在上面的示例(带有 MemorySSA 注释)中,%a 和 %b 是等效的,而 %c 不是。所有三个加载都是来自相同指针的相同类型,但它们并不都从相同的内存状态加载。加载 %a 和 %b 从存储定义的内存(Memory 1)中加载,而 %c 从函数调用定义的内存(Memory 2)中加载。GVN 也可以检测到这些冗余,但它依赖于更昂贵且更不一般的 MemoryDependenceAnalysis。
尽管有这些和其他改进,NewGVN 仍然没有得到广泛使用,主要是因为它缺乏部分冗余消除 (PRE),并且存在错误。
实现 PRE
我们的主要贡献是为 NewGVN 开发了一个 PRE 阶段(请点击此处查看)。我们的解决方案依赖于对 Phi-of-Ops 进行泛化。它执行了一个特殊的 PRE 案例,其中指令依赖于 phi 指令,并且在所有到达路径上都存在等效的值。这是通过两个步骤完成的:phi 翻译和 phi 插入。
phi 翻译包括在每个块的前驱上下文下评估原始指令。Phi 操作数被替换为从前驱传入的值。如果翻译后的指令等效于常量、函数参数或支配前驱的另一条指令,那么该值在前驱中可用。
如果该值在每个前驱中都可用,则在 phi 翻译之后会发生 phi 插入。此时,会构造一个等效值的 phi,并用来替换原始指令。以下示例说明了整个过程。
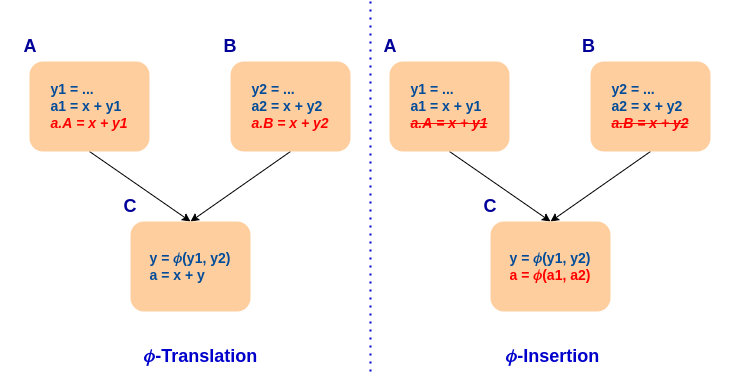
我们的泛化消除了对依赖 phi 的需求,并且引入了在指令部分冗余的情况下插入缺失值的能力。为了防止代码大小增加(忽略插入的 phi 指令),只有在需要插入唯一一个 phi 时才会进行插入。以下示例说明了整个过程。
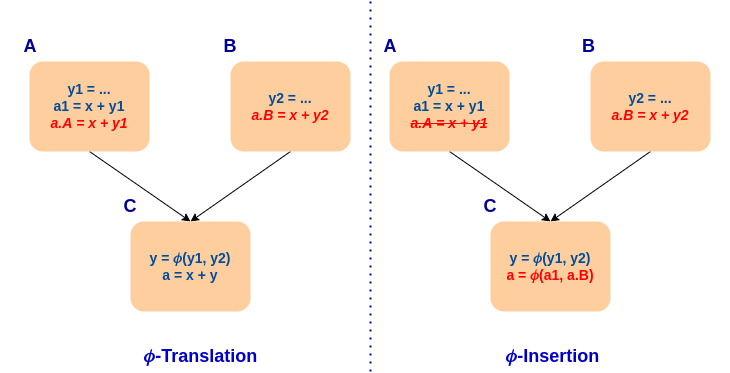
将 PRE 集成到现有框架中也使我们能够免费获得循环不变代码移动 (LICM)。乐观假设结合 PRE,允许 NewGVN 推测性地将指令从循环中提升。另一方面,GVN 中的 LICM 依赖于使用 LoopInfo,并且只能处理非常具体的案例。
缺失的功能
我们 PRE 实现缺少的两个主要功能是关键边拆分和加载强制转换。关键边拆分是确保我们不会将指令插入到不会使用它们的路径中。目前,我们的实现只会在这种情况下放弃。加载强制转换允许我们检测不同类型加载值的等效性,例如 i32 和 float 的加载,然后使用转换操作强制转换加载的类型。
实现这些功能的难度在于,NewGVN 被设计为在单独的步骤中执行分析和转换,而这些功能需要在分析阶段修改函数。
结果
我们使用自动基准测试工具 Phoronix 测试套件 对我们的实现进行了评估,从中我们选择了一组 20 个 C/C++ 应用程序(列在下面)。
| aircrack-ng | encode-flac | luajit | scimark2 |
| botan | espeak | mafft | simdjson |
| zstd | fftw | ngspice | sqlite-speedtest |
| crafty | john-the-ripper | quantlib | tjbench |
| draco | jpegxl | rnnoise | graphics-magick |
使用了默认的 -O2 管道。编译之间的唯一区别是使用的数值编号通道。
尽管缺少功能,但我们观察到我们的实现平均比 GVN 性能提高了 0.4%。但是,需要指出的是,我们的解决方案还没有经过微调,以考虑优化管道的其余部分,这导致了一些情况下,与 GVN 和现有 NewGVN 相比,我们的实现出现了倒退。最严重的案例是 jpegxl,我们的实现平均比 GVN 性能下降了 10%。需要注意的是,这是一个特例,排除 jpegxl 后,大多数倒退最多为 2%。不幸的是,由于时间限制,我们无法更详细地研究这些案例。
未来工作
未来,我们计划实现上述缺失的功能,并微调执行 PRE 的启发式算法,以防止结果部分讨论的倒退现象。解决这些问题后,我们将把我们的实现上游,使我们离重振 NewGVN 更近了一步。